An example This example of a package body file is not complete, but it should give you an idea of how to write a package body file that has the correct outline and parsing etc.
An example of a pkg file (that contains both header and body in one) can be seen here.
Directory structure for you pl sql code. The best thing you can do is have your schemas in separate directories - one directory per schema. This way it will be easy for the editor to find all of your packages per schema.
Package Naming Format The editor expects your package files to be named schemaname_pkgname.pkb. If you don't name them in this way, there is no guarantee that the editor will correctly assign your package to its schema. You can override this by going to the preferences and assigning particular packages to particular files.
Database access support. There are several components of database access support.
Configuring default access to the database These connection details will be used by each project if you do not set project specific connection settings. They can be overridden by specifying project specific properties. This involves navigating to the Database Connectivity Setup Preference Page within the PL/SQL Preferences. Once you have navigated there, you must specify an Oracle driver. The default driver that is supplied with the plugin is "oracle.jdbc.driver.OracleDriver". You must also specify the database connect url. It must be in the format "jdbc:oracle:thin:@hostname:1521:SID" where the hostname is the name of your database host (or localhost if local), the 1521 should map to your database port (although usually 1521 is the correct port - it is the default) and SID is your Service Identifier, the database id if you will. You can leave the initial and max connections as 1 and 1, since I don't think it should be possible to use more than one at a time within the eclipse architecture. This is built in for future enhancements where the same connection might be used for separate purposes.
Configuring the dba user for database procedure/function content assist This involves modifying the user name and password on the same Database Connectivity Setup Preferences Page. This can also be overridden per project on the project properties Database Connectivity Setup Properties Page. The user name and password here should have dba access so they can query the schema, package and procedure tables to allow content assist to present these methods to the user.
Configuring each schema to allow upload of code to the database. The way that this had to be done prior to release 0.4.0 involved modifying the schema objects in the Schema Mapping Preference Page screen located on the properties page of a PlSql project. Each project may have different schemas, so each project will need to be configured individually. Each schema has a name, a list of comma separated locations and a password. The schema name is the user and the password is the password for that user. The database connection string is the same as the dba database connection string and the driver is the same too. By setting the password for a schema, you allow yourself to upload code for that schema.
If this description is too brief, try a visually guided walkthrough. HOWEVER, NEW FEATURE! As of 0.4.0 you can right click in the editor of the open file you wish to set to a new schema and select the <Change Schema for Package> item from the popup menu. This will allow you to specify the name of the package (which you can change to whatever package name you want, although it will be defaulted to the name it believes is correct) and the schema. This will update the schema mappings to allow code loading and schema DML to be executed. The old way still works, but the new way is much easier.
Database Execution
Executing sql to the database You can execute the selected block of text as a set of commands to the database by selecting the block of text and pressing Ctrl-Alt-E or right clicking and selecting Execute PL/SQL from the immediate menu. You may also execute a block separated by empty lines above and below by having the cursor on the block between the empty lines and pressing Ctrl-Alt-E or right clicking and selecting Execute PL/SQL from the immediate menu.
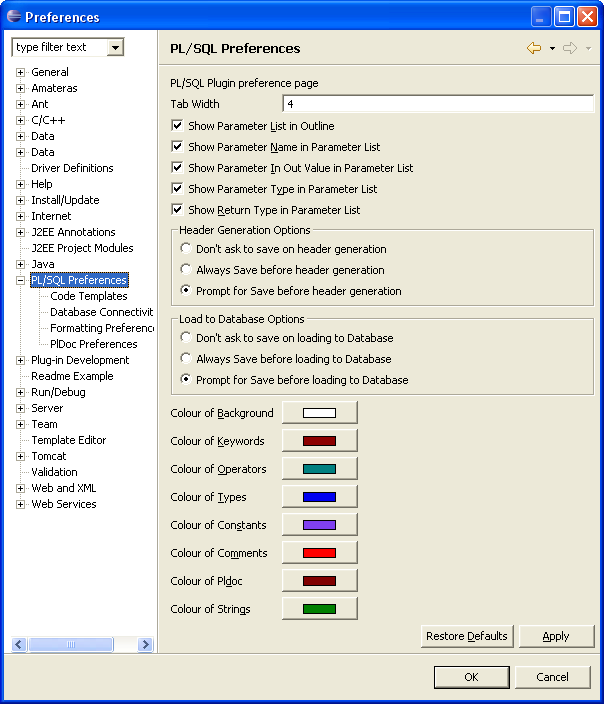
Loading a file to the database The editor allows you to load the package body or header that is currently open to the database. In the main preferences page (seen here) you can choose whether the load to database action should ask you to save a dirty file before continuing. There are three options
- Don't ask - This means the load to database will take the current file without saving it
- Always save - This means the load to database will always save a dirty file before generating the header.
- Prompt for save - This means that if the file is dirty the action will ask the user if s/he wants to save prior to continuing. If the user says yes the file will be saved, otherwise it will not, but the action will continue regardless
Viewing DBMS Output You can turn dbms output on for each schema in which you are working. In order to see (turn on) any dbms output you must open a file that refers to that schema (and you can check this by pressing the “Display Debug Information” button (
 ).
Then you must open the DbmsOutput view (in Show View). Once this is
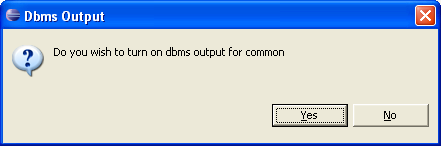
open you must press the button to turn it on (seen in this image)
and respond yes to the dialog
asking you if you want to turn on that dbms output. This can be
used a a double check to ensure you are turning on dbms output for
the right schema. Turning it off simply uses the other button on
the view.
).
Then you must open the DbmsOutput view (in Show View). Once this is
open you must press the button to turn it on (seen in this image)
and respond yes to the dialog
asking you if you want to turn on that dbms output. This can be
used a a double check to ensure you are turning on dbms output for
the right schema. Turning it off simply uses the other button on
the view.
{kind=link}
{kind=link}
{kind=link}
Code Editing
Code Folding Currently the plsqleditor provides code folding so that you can right click on a selected block and make it folding. You can also specify a code fold by typing in the correct format folding. This is in the format of the string "--#startFolding" on a line all by itself to start and the string "--#endFolding" on a line all by itself to finish.
Code folding will be updated eventually when I have implemented a parser, so that code folding will also fold on blocks, ifs, loops, functions etc.Uppercasing You can uppercase by pressing the uppercase button on the toolbar, or right clicking and selecting uppercase from the PlSqlEdit menu, or pressing Ctrl-Alt-U while you have selected the block to uppercase.
Lowercasing You can lowercase by pressing the lowercase button on the toolbar, or right clicking and selecting lowercase from the PlSqlEdit menu, or pressing Ctrl-Alt-O while you have selected the block to lowercase.
Commenting Code You can add a comment (--) to a line, or series of lines by right clicking and selecting "add a single comment to the beginning of the line" from the PlSqlEdit menu, or pressing Ctrl-/ while you have the cursor over the line you want commented, or you have selected a block to comment.
Uncommenting Code You can remove a comment (--) from a line, or series of lines by right clicking and selecting "remove a single comment from the beginning of the line" from the PlSqlEdit menu, or pressing Ctrl-Shift-/ while you have the cursor over the line you want uncommented, or you have selected a block to uncomment.
Shifting Code left and right You can shift a set of lines of code right by selecting the block of code you wish shifted and pressing Tab. The functionality is also available in the right click popup menu under the name "Shift Right". This will shift the code one tab to the right. You can shift the code to the left similarly by pressing Shift-Tab, or selecting the "Shift Left" action from the right click popup menu.
Generating Headers for package bodies The editor allows you to generate headers for package body files. In the main preferences page (seen here) you can choose whether the header generation action should ask you to save a dirty file before continuing. There are three options
- Don't ask - This means the header generation will take the current file without saving it
- Always save - This means the header generation will always save a dirty file before generating the header.
- Prompt for save - This means that if the file is dirty the action will ask the user if s/he wants to save prior to continuing. If the user says yes the file will be saved, otherwise it will not, but the action will continue regardless
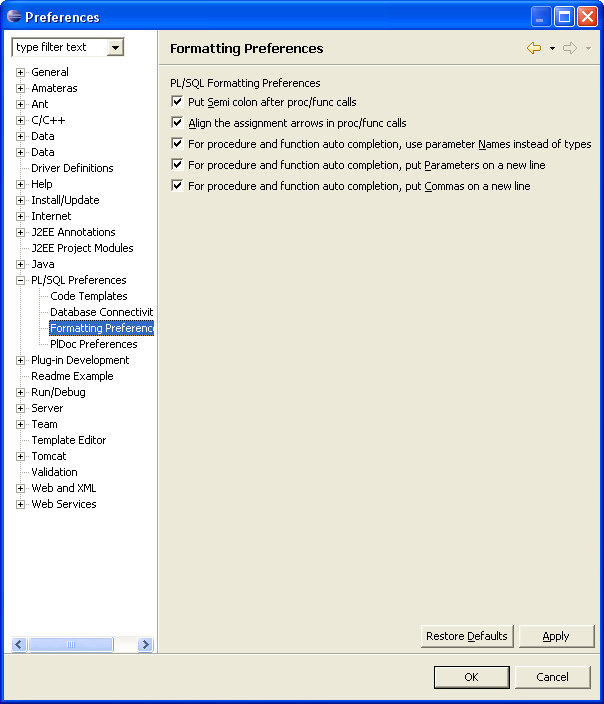
Auto completing procedures and functions You can auto complete functions with the standard Ctrl-Space content assist. The format that these come out in depends on the settings you select from the Formatting Preferences (seen here).
- The "Put Semi colon after proc/func calls" allows the content assist to generate the semi colon after completion.
- The "Align the assignment arrows in proc/func calls" allows the content assist to ensure all the assignment arrows (=%gt;) to be in the same column.
- The "For procedure and function auto completion, use parameter Names instead of types" allows the content assist to generate "pis_name => pis_name" instead of "pis_name => blah%TYPE"
- The "For procedure and function auto completion, put parameters on new line" allows the content assist to put each parameter declaration on a new line.
- The "For procedure and function auto completion, put commas on new line" allows the content assist to put the commas in front of each parameter rather than after, i.e ",pis_name => t_type" instead of "pis_name => t_type,"
{kind=link}
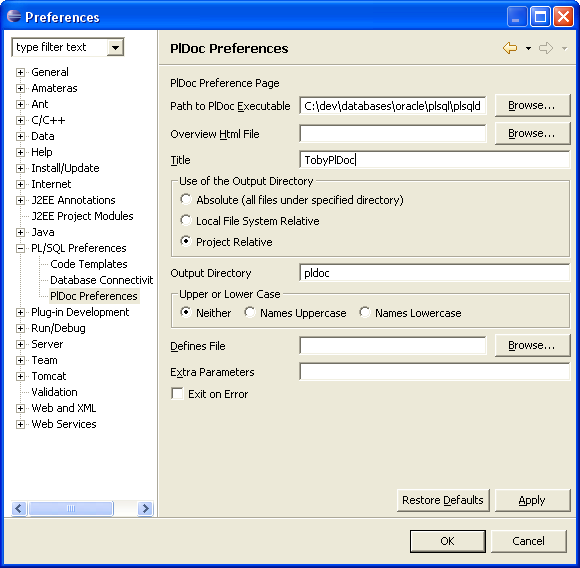
Pl Documentation Generation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}